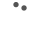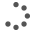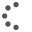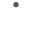


Quand les données big-data de téléphonie mobile servent la statistique publique
Si le recensement de la population organisé par l’Insee permet d’estimer la population résidente, il ne permet pas d’estimer la population effectivement présente sur une zone géographique donnée à un instant donné, puisqu’il ne tient pas compte des flux touristiques et des comportements d’activité. Or la population présente constitue un indicateur crucial pour observer et piloter une grande variété de phénomènes à la fois sociaux (la mixité sociale par exemple), économiques (la mobilité domicile-travail), environnementaux (la pression anthropique) ou encore relatifs à des infrastructures (les besoins en logements et transports). Ainsi par exemple, connaître la population présente dans une région touristique permet d’anticiper plus finement les fluctuations de besoin en logements, en transports ou encore en eau.
Dans ce contexte, les données de téléphonie mobile offrent des perspectives prometteuses puisqu’elles indiquent la localisation des abonnés. En effet, pour communiquer, un appareil mobile échange des ondes radio un réseau cellulaire : selon sa localisation, l’appareil mobile échange avec une antenne et en se déplaçant peut changer d’antenne sans interrompre la communication. En connaissant l’antenne qui est mobilisée à un instant t par un appareil mobile et les caractéristiques de cette antenne, il est ainsi possible d’affecter une localisation plus ou moins précise à l’individu correspondant. La précision dépend de la répartition locale des antennes dans le territoire et des informations disponibles sur leur configuration. Deux types de données de téléphonie mobile peuvent être utilisées : (a) les données actives, ou Call Details Records, qui correspondent à une action délibérée de l’abonné (appel, SMS, etc.) ; (b) les données de signalisation d’autre part, ou Signaling Data, qui sont générées toutes les 10 à 200 minutes sans action nécessaire de l’abonné, et qui correspondent aux diverses connexions de l’appareil mobile au réseau mobile (télécommunication et internet 2G, 3G, 4G). Ce sont ce type de données qui ont permis à plusieurs chercheurs d’évaluer les performances du réseau de transport d’Île-de-France, d’analyser les relations interpersonnelles ou d’estimer le nombre de touristes et leur durée de séjour comme le font la Banque de France et le Ministère de l’économie et des finances.
Grâce à ces données et des compétences de « data-scientist », on peut ainsi construire des cartographies assez précises de la population présente. Mais pour cela, il est essentiel de construire préalablement un modèle statistique adapté.
A la recherche d’un modèle statistique adapté
Un téléphone se connecte toujours à l’antenne dont il est le plus proche. On peut en tirer une partition de l’espace appelée « tessellation de Voronoï ». Cette partition s’appuie sur un ensemble de points donnés, appelés « graines ». En affectant chaque point du plan à la graine la plus proche, il apparaît alors des polygones : chaque polygone contient l’ensemble des points affectés à une même graine. La tesselation de Voronoï est utilisée dans l’exploitation des données de téléphonie mobile, en considérant que chaque antenne correspond à une graine. Lorsqu’un appareil mobile se connecte à une antenne, il peut alors être admis que l’individu se situe dans le polygone de Voronoï associé. Cette représentation a le mérite de réaliser une partition de l’espace mais ne correspond à aucun découpage administratif, dépend largement de la densité des antennes et n’approxime qu’imparfaitement la couverture réelle des antennes (portée, superposition, etc.). Les données brutes ne permettent donc qu’un maillage géographique assez grossier de la population présente.
Figure n°1 : Une tessellation de Voronoï
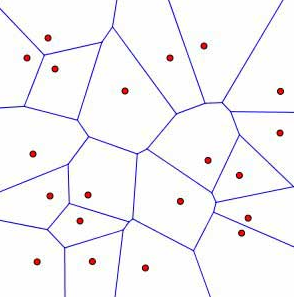
On peut cependant, à travers à une modélisation, obtenir une précision bien meilleure dans la localisation des individus en recoupant ces données brutes avec des informations sur les caractéristiques et le fonctionnement du réseau. Ainsi, dans une étude menée par l’Insee en partenariat avec Orange Labs, on a réussi à affiner la localisation des événements observés en mobilisant des données de la statistique publique. Pour cela, le territoire considéré est d’abord découpé en des carreaux de 500m de côté, selon une grille fine et régulière. Puis chacun des carreaux est caractérisé selon la nomenclature topologique de l’IGN (bâti indifférencié[1], routes, cours d’eau, etc.). On peut alors faire plusieurs hypothèses raisonnables : par exemple, qu’un portable en activité la nuit appartient plus probablement à certains types de carreaux que d’autres ou, autre exemple, qu’il y a plus de chances qu’un individu envoyant un SMS se trouve dans un quartier résidentiel avoisinant que dans un parc. Le modèle probabiliste ainsi conçu localisera chaque téléphone mobile en activité, non plus strictement selon les coordonnées de l’antenne la plus proche, mais sur plusieurs carreaux avoisinant, en affectant à chacun d’eux une probabilité de présence plus ou moins grande.
Ce modèle a été estimé à partir des Call Details Records de 18,5 millions de clients de l’opérateur Orange sur le mois de septembre 2007, soit près de 3 milliards d’évènements téléphoniques. À l’échelle de la France, l’agrégation de toutes les probabilités de présence selon ce modèle offre ainsi la carte suivante (à droite), relativement au modèle classique des Voronoïs (à gauche) :
Figure n°2 : La distribution de la population à partir des voronoïs (à gauche) et à partir d’un modèle probabiliste (à droite)
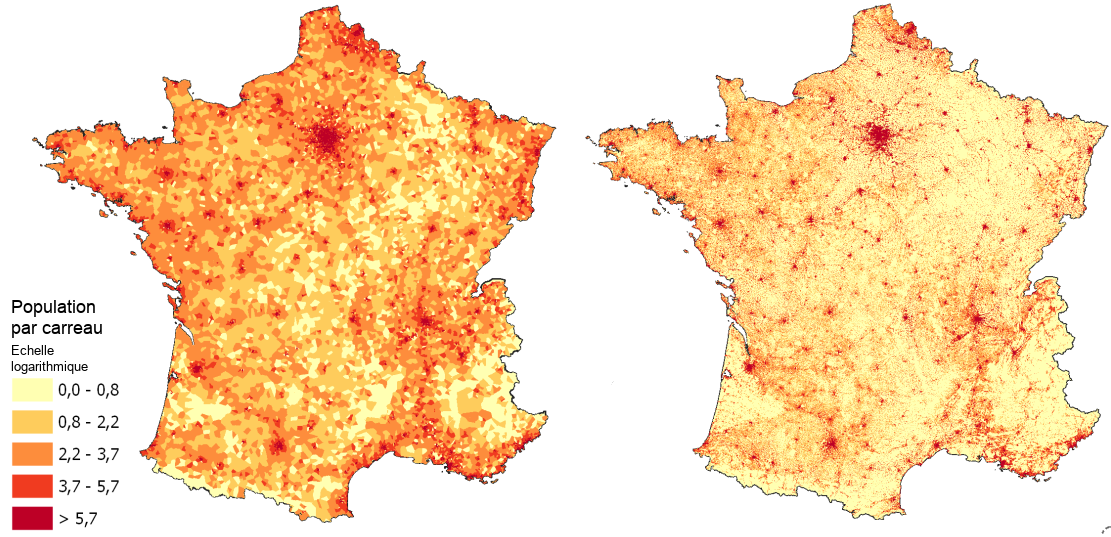
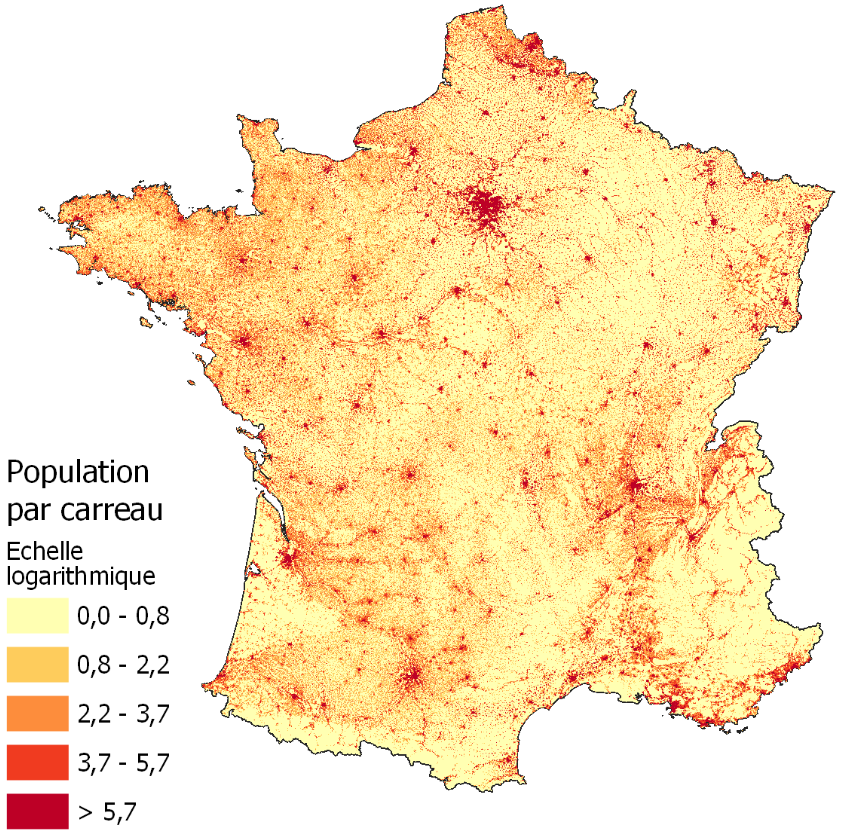
Outre la finesse accrue qu’offre le modèle probabiliste, comme en témoigne la granularité plus fine de la cartographie correspondante, il apparaît que les probabilités de présence ainsi estimées sont en moyenne corroborées par la distribution de référence calculée à partir d’une source fiscale (les Revenus fiscaux localisés) et représentée dans la figure 3.
Figure n°3 : La distribution de la population à partir d’une source fiscale (RFL)
On pourrait faire encore mieux…
Une analyse approfondie montre que les résultats obtenus à travers le modèle probabiliste sont d’autant plus robustes que la zone étudiée est peu densément peuplée, soit davantage dans les zones rurales et péri-urbaines que dans les zones urbaines. Dans ces dernières en effet, le bâti est plus largement uniforme, ce qui limite la possibilité de discriminer les carreaux et donc les probabilités de présence. La prise en compte des données plus riches de Signaling Data et d’informations techniques sur la couverture des antennes, ainsi que la distinction entre les différents types de bâti devraient permettre de consolider encore la finesse et la robustesse des estimations de présence de population.
Les données en notre possession ne portaient ni sur l’ensemble des abonnés, ni sur l’ensemble des opérateurs, et elles ignoraient les individus sans téléphone portable. Il a donc fallu procéder à des redressements afin de rendre les estimations de population comparables à la source fiscale. Ce n’est pas aisé, puisque cela suppose d’avoir des informations complémentaires, notamment démographiques, qui soient appariables et disponibles à un niveau géographique très fin. Nous avons utilisé pour cela le fichier clients (CRM) d’Orange au niveau départemental. Par ailleurs, les données de téléphonie mobile sont rarement suffisantes pour déterminer les caractéristiques des abonnés (métier, âge, etc.) ou pour qualifier les lieux (résidence, transit, activité) et les motifs de ses déplacements (conduite à l’école, courses, etc.). Il faudrait développer des algorithmes ad hoc, par exemple pour distinguer les touristes des personnes résidentes à partir de leur fréquence de passage sur le même lieu.
Il y aura cependant des difficultés de nature juridique. L’exploitation des données de téléphonie mobiles pose en effet un risque pour le respect de la vie privée des abonnés puisqu’il est relativement aisé de ré-identifier un abonné à partir de l’historique des traces numériques laissées par son portable ce qui impose d’agréger suffisamment l’information - au risque d’une perte en finesse - pour se conformer à des garanties juridiques (RGPD ou directive Eprivacy).
En définitive, les données de téléphonie mobile ouvrent un champ novateur de la statistique publique : combinées à diverses sources de données, elles peuvent déboucher sur des indicateurs de présence humaine selon une régularité temporelle et une granularité spatiale inégalées. Que ce soit pour mesurer la pression anthropique sur un espace ou une ressource naturelle, anticiper des besoins en services ou observer finement des mobilités, ces indicateurs seraient tout particulièrement utiles dans le champ de l’action sociale et environnementale. Pour poursuivre l’expérimentation, l’Ifsttar[2], l’Insee, Orange labs, et Géographie-cités lancent en janvier 2020 le projet MobiTIC, financé par l’Agence Nationale de la Recherche. Ce projet de 42 mois visera à produire une cartographie dynamique de présence, en caractérisant les lieux par leur usage et fréquentation, avec un zoom notamment sur les quartiers des politiques de la ville et les zones péri-urbaines.
* Les auteurs remercient Orange Labs, et en particulier Zbigniew Smoreda, ainsi que le SSP Lab de l’Insee.
[1] Soit essentiellement l’habitat mais aussi les écoles, les hôpitaux, les musées, etc.
[2] Institut français des sciences et technologies des transports, de l'aménagement et des réseaux.
Références
Avouac R., Sakarovitch, B., Sémécurbe, F. & Smoreda, Z. (2019). A bayesian approach to improve the estimation of population using mobile phone data. Document de travail.
Aguiléra, V., Allio, S., Benezech, V., Combes, F. & Milion, C. (2014). Using cell phone data to measure quality of service and passenger flows of Paris transit system. Transportation Research Part C: Emerging Technologies, 43(2), 198–211
Ahas, R., Silm, S., Järv, O., Saluveer, E. & Tiru, M. (2010). Using Mobile Positioning Data to Model Locations Meaningful to Users of Mobile Phones. Journal of Urban Technology, 17(1), 3–27
Bojic, I., Massaro, E., Belyi, A., Sobolevsky, S. & Ratti, C. (2015). Choosing the Right Home Location Definition Method for the given Dataset. Springer International Publishing, pp. 194–208
Cousin, G. & Hillaireau, F. (2018). Can Mobile Phone Data Improve the Measurement of International Tourism in France? Economie et Statistique, 505-506, 89–107.
Grauwin, S., Szell, M., Sobolevsky, S., Hövel, P., Simini, F., Vanhoof, M., Smoreda, Z., Barabási, A.L. & Ratti, C. (2017). Identifying and modeling the structural discontinuities of human interactions. Scientific Reports, 7
Montjoye, Y. A. (de), Hidalgo, C.A., Verleysen, M. & Blondel, V. D. (2013). Unique in the Crowd: The privacy bounds of human mobility. Science Report, 3
Sakarovitch, Benjamin, Marie-Pierre De Bellefon, Pauline Givord, and Maarten Vanhoof. 2019. Allô, où es-tu ? Estimer la population résidente à partir de données de téléphonie mobile, une première exploration. Economie et Statistique.
Auteurs



Articles liés
-
- Statisticienne ou romancière, pourquoi choisir ?Tribune - Statisticienne ou romancière, pourquoi choisir ? Lire la suite >
-
-
- Stratégie chinoise et application dans la guerre commercialeTribune - Stratégie chinoise et application dans la guerre... Lire la suite >
-
- Dix principes directeurs pour concilier l’illusion et la raison : de Houdini à ColumboTribune - Dix principes directeurs pour concilier l’illusion... Lire la suite >
-
- Quand Bourdieu enseignait la sociologie à l’ENSAE et quelques héritages ultérieursTribune - Quand Bourdieu enseignait la sociologie à l’ENSAE... Lire la suite >
-
- Pour la défense des principes fondateurs de la statistique publiqueTribune - Pour la défense des principes fondateurs de la... Lire la suite >
-
-
- Une brève histoire d’internet : d’utopies en dystopiesTribune - Une brève histoire d’internet : d’utopies en... Lire la suite >
-
- Les plateformes sont-elles trop puissantes ? Le cas des hôteliersTribune - Les plateformes sont-elles trop puissantes ? Le... Lire la suite >
-
- Compter son travail, travailler sans compter, loin des contes de féesTribune - Compter son travail, travailler sans compter, loin... Lire la suite >
-
-
- 2020, année auto-descriptive… des chiffres qui nous donnent à lire !Tribune - 2020, année auto-descriptive… des chiffres qui... Lire la suite >
-
-
- Plateformes musicales et rémunération des artistes*Tribune - Plateformes musicales et rémunération des... Lire la suite >
-
- Covid-19 : « Il faut un programme d’urgence pour l’Europe »Tribune - Covid-19 : « Il faut un programme d’urgence pour... Lire la suite >
-
- La pratique des prix abusifs dans les temps de détresseTribune - La pratique des prix abusifs dans les temps de... Lire la suite >
-
- Les risques liés à la cyber-délinquance financièreTribune - Les risques liés à la cyber-délinquance financière Lire la suite >
-
- Coronavirus et comportement individuelTribune - Coronavirus et comportement individuel Lire la suite >
-
- Les Dinosaures du changement climatique (Les compagnies pétrolières vont-elles se réinventer ?)Tribune - Les Dinosaures du changement climatique (Les... Lire la suite >
-
- Peut-il y avoir à nouveau une crise financière ?Tribune - Peut-il y avoir à nouveau une crise financière ? Lire la suite >



















Aucun commentaire
Vous devez être connecté pour laisser un commentaire. Connectez-vous.